
The Best Fluffy Pancakes recipe you will fall in love with. Full of tips and tricks to help you make the best pancakes.

Web Scraping
Web Scraping is the method which is used to obtain large amount of data from websites over internet. In most of the cases the data in unstructured data, so it is stored in HTML format in order to optimize the data is converted into spreadsheets for further usage.
There are There are different methods to perform web scraping and obtain data from the web. In this version of evolving industries, we can easily find the APIs creating the scraping from scratch. Web scraping requires two parts, namely the crawler and the scraper. The crawler is an artificial intelligence algorithm that browses the web to search for the particular data required by following the links across the internet.
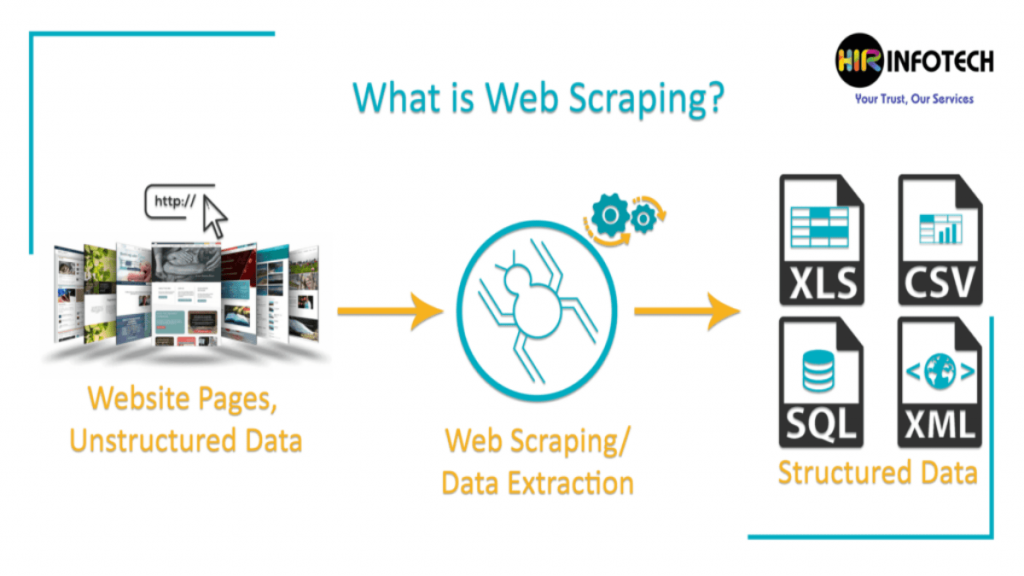
This represents the best and most convenient way to understand the working of web scraping. As we can see here that the data scraping is divided into three segments, In the very first segment unstructured data is being extracted from different websites. In the second process, the extracted data collection and storage is being done. At last, after collecting the data all the data is being converted into a structured way. This is the literal meaning of web scraping. Web Scrapers are the tools by which scraping is done. Web Scraping can be done using python language.
Types of web scrapers
Pre-built Scrapers
The tools available to build your own web scraper still require some advanced programming knowledge. The scope of this knowledge also increases with the number of features you’d like your scraper to have. There are many sorts of self built or pre built scrapers present.
Browser extension Scrapers
Browser extensions are app-like programs that can be added to your browsers such as Google Chrome or Firefox. Some popular browser extensions include themes, ad blockers, messaging extensions and more.
Web scraping extensions have the benefit of being simpler to run and being integrated right into your browser.
User Interface Scrapers
The user interface between web scrapers can vary quite extremely.
For example, some web scraping tools will run with a minimal UI and a command line. Some users might find this unintuitive or confusing.
Local Scraper
Local web scrapers will run on your computer using its resources and internet connection. This means that if your web scraper has a high usage of CPU or RAM, your computer might become quite slow while your scrape runs. With long scraping tasks, this could put your computer out of commission for hours.
Information is the most valuable commodity in the world. But in order to gain information, you need data! Unfortunately, all the abundant data on the internet is not open and available for download. So, Web scraping is the ultimate way to collect this data. Data once collected can be further analyzed to get valuable insights into almost everything! We have listed down 5 business benefits that businesses can leverage with ethical web scraping, but before that let’s see why web scraping is the need of the hour!
Anonymous
How to improve web Scraping?
- If possible avoid using the images in content if its really needed store in a place where its private and cannot be scrapped.
- Terminate each session after scrapping never leave the session, make sure it is closed.
- Avoid using scraping in multiple browser windows
- Make sure the data is scrapped properly without any suspicious extension.
Be aware of these mistakes!
- Don’t use broken links
- Stay away from the sites where you can observe breakage or suspicious broken links.
- Only use scrapping from websites having iframe
- Make sure do not just use the content which is abusive or portraying a wrong message to the society, make sure using proxies while scrapping for your own safety.
Web scrapping using Python 3.0

There are many ways one can do web scrapping but there are few restrictions and chances of committing mistakes if there are any human intervention. Web scraping with python is more convenient.
SCRAPING WITH SELENIUM
Python is widely known to be useful in many things in tech, but web scraping happens to be one of the major domains where python programming thrives.
WHAT IS SELENIUM?
Selenium is an umbrella project for a range of tools and libraries that enable and support the automation of web browsers.
It provides extensions to emulate user interaction with browsers, a distribution server for scaling browser allocation, and the infrastructure for implementations of the W3C WebDriver specification that lets you write interchangeable code for all major web browsers.
Meanwhile, selenium is not the only module used for web scraping with python, there are other major modules that are also as popular as selenium. However there are cons and pros for each of them, you just need to know the one you need at every occasion. We’ll discuss a brief comparison of these modules further on.
The 3 most popular python modules used for web scraping are as follows:
SCRAPY:
Scrapy is efficient and portable. However it’s major con is that it’s not user friendly, especially for beginners.
BEAUTIFUL SOUP:
Beautiful soup is easy to learn and understand. However it does have some cons too: Beautiful soup requires dependencies and it’s less efficient than Scrapy.
SELENIUM:
In this post we’ll use selenium as our module for web scraping with python, perhaps in my next web scraping post we’ll adopt any of the other modules mentioned above.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import requests
from pprint import pprint
def get_wiki():
#get the preferred keyword
keyword = input('Enter a keyword to search:\n')
link_dec = input('Do you need links? Kindly enter yes or no:\n').lower()
#create path instance and create the driver path
d_path = Service('/home/you/Desktop/my_scraper/web_driver/chromedriver')
driver = webdriver.Chrome(service = d_path)
#get the page and enter a keyword to search
driver.get('https://en.wikipedia.org/wiki/Main_Page')
search_box = driver.find_element(By.NAME, 'search')
search_box.send_keys(keyword)
search_box.send_keys(Keys.ENTER)
time.sleep(3)
#get the main content
main_data = driver.find_element(By.ID, 'content')
pprint(main_data.text)
def show_links():
"""Get the links available in the contents"""
links = driver.find_elements(By.TAG_NAME, 'a')
for link in links:
print(link.get_attribute('href'))
if link_dec == 'yes':
show_links()
else:
pass
driver.quit()
get_wiki()Credits:- geeks for geeks
I hope you had a great learning by reading few things about Web Scraping.
To learn more things about new and tech related things you can hover through our website.
Links :- Web scraping with python :- Web Scraping with Python – Beautiful Soup Crash Course – YouTube
Web Scraping tutorial:- Web Scraping With Python | Python Tutorial | Web Scraping Tutorial | Python Beautifulsoup | Edureka – YouTube